Architecture
Five subsystems wired through Claude Code as the central orchestrator. Each subsystem owns one capability and communicates through plain files in the repo — no in-memory state, no inter-process messaging.

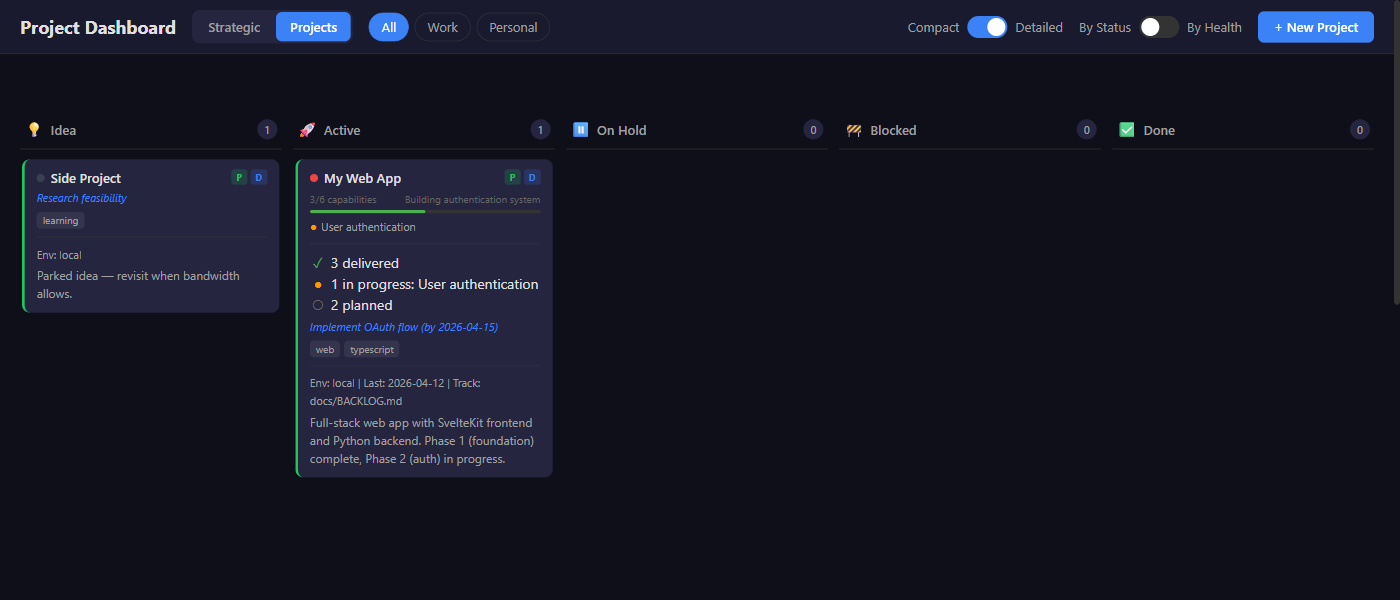
Tracking
4-tier hierarchy: TELOS goals → projects → capabilities → work items. Reconciliation engine recalculates health and generates nudges. Dashboard renders the live view.
Briefing
Parallel morning gatherers (weather, news, project status), one assembler, TTS generation, multi-channel delivery, watchdog that recovers from missed runs.
Knowledge
Brain entries (cross-project knowledge graph), transcript archive, SessionStart hook that injects recent context into new sessions. /learn, /recall, /capture slash commands.
Delivery
Discord webhooks, SMTP email, ntfy push notifications, Edge TTS audio. All credentials in the OS keyring, never in .env files.
Commands
Slash commands surfaced into Claude Code. /open-ticket, /close-ticket, /backlog, /learn, /recall. The user-facing interface to the system.